
(a) 判定ノード

(b) 処理ノード
遺伝的ネットワークプログラミング(Genetic Network Programming, GNP)の紹介とソースコード作成手順
An introduction to Genetic Network Programming (GNP) and its coding procedure
修正:14.07.08
生物の進化のメカニズムを工学に展開したものが進化論的計算手法です.
進化論的計算手法の代表的なものに,
があります.これらはおもにストリング構造や木構造によって解を表現しています.
遺伝的ネットワークプログラミング(Genetic Network Programming, GNP)[3,4]は,ネットワーク構造(有向グラフ構造)で解(プログラム)を表現する進化論的計算手法として提案されましたが,GA,
GPの拡張という点はもちろん,生物の脳の構造がネットワークになっていることから,プログラムの表現能力の点で優れた能力を持っているのではないかという考えに基づいています.
本ページでは,基本的な構造とC言語でのプログラムの表現方法について説明したいと思います.
GNPのテンプレートコード ver. 1.0.1 はこちら(14.07.08 修正版)
これ以降の解説をまとめてサンプルプログラムを作成しました.
プログラム全体に一貫性を持たせるため,変数名等,解説と一部異なる箇所がありますが,機能に違いはありません.
GNPの構造と特徴
構造の基本単位:ノード
1. プログラムを判定ノード(図1(a))および処理ノード(図2(b))と呼ばれるノードで構成します.たとえば,判定ノードはセンサの情報を入力してif-thenの条件分岐を行います.処理ノードは行動決定を行います.
(a) 判定ノード |
(b) 処理ノード |
| 図1 ノードの例 | |
ノードの情報表現:遺伝子構造
2. 各ノードの情報は以下のような遺伝子構造(配列)で表現します.注1
| NT | ID | d | CA | CB | CC |
図2 遺伝子構造(配列)
遺伝子構造とノードの対応は図3をご覧ください.
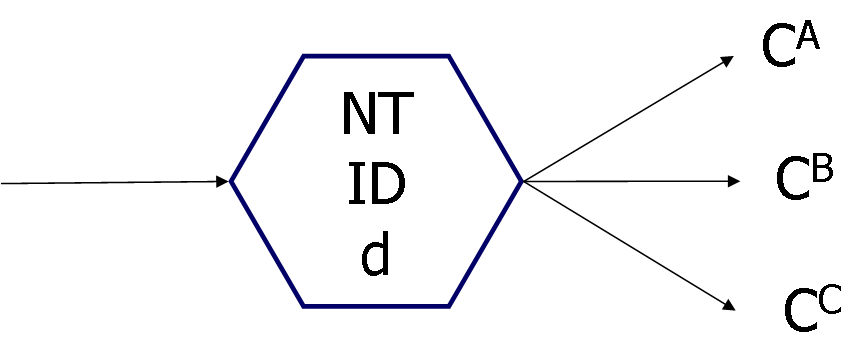

図3 ノードと遺伝子の対応
NT:ノードの種類を表します(1: 判定ノード, 2: 処理ノード)
ID:ノード関数(機能)を表します.
たとえば,図1では,
NT=1(判定ノード)で,ID=1なら「ロボットの前に障害物があるか?」を判定するノード
NT=1(判定ノード)で,ID=2なら「エネルギー残量」を判定するノード
NT=2(処理ノード)で,ID=1なら「前進」の行動決定をするノード
NT=2(処理ノード)で,ID=2なら「右折」の行動決定をするノード
と設定することができます.
d: ノードの実行にかかる時間.実世界で,判定や処理を行う際にかかる時間を遅れ時間として設定することができます.その他,ノード遷移のループに対処する重要な役割があります.現在のところ,遅れ時間の主要な役割は後者です.後ほど説明します.
問題によりますが,
判定ノードの遺伝子d(遅れ時間)=1
処理ノードの遺伝子d(遅れ時間)=5
などと設定します.
CA, CB, CC: ノードの接続先の番号.GNPの総ノード数がN個のとき,各ノードは0からN-1の番号をもっています.したがって,CA=15であれば,ノード番号15へ接続があることを示します.
判定ノードの場合,判定結果がAであれば ノード番号CAへ遷移します.判定結果がBであればCBです.図1(a)のエネルギー残量を判定するノードの場合,「エネルギーがmax」であればCAへ遷移,「high」であればCBに遷移,「low」であればCCへ遷移,となります.
処理ノードの場合,条件分岐がありませんので,「前進」や「右折」などの行動決定を行った後,CAのノードへ遷移します(CB,CCは使用しない)
C言語で1個のノードの遺伝子情報を表現すると,
struct gene_structure{
int node_type;
int node_func;
int node_delay;
int connect[NUM_BRANCH];
}
/* NUM_BRANCHは判定ノードの最大分岐数 */
となります.プログラム作成上見やすいように構造体で表現しています.
これでノードを1個表現することができます.
注1 参考文献[3,4]等では接続の遅れ時間が存在しますが,現在のところ使用しないことが多く,ここでは省略しています.
有向グラフの生成
1.ノード変数の宣言
多くの判定ノードと処理ノードを図3のようにネットワーク構造状に連結することでプログラムを表現します.
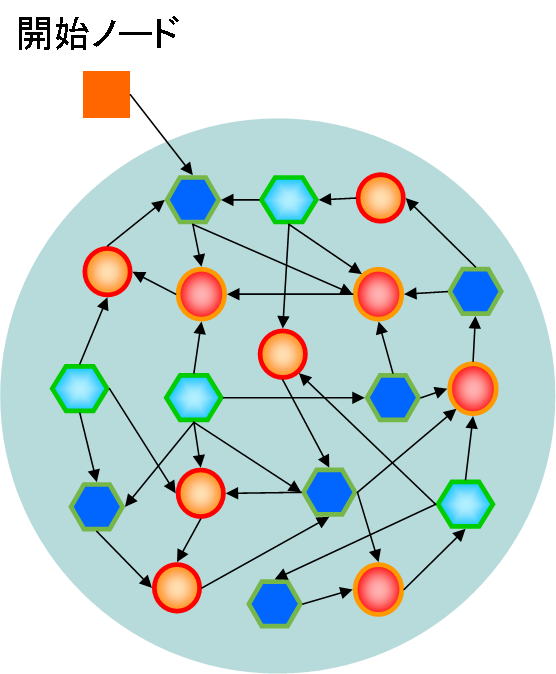
図3 GNPの基本構造
まず,開始ノードを1個用意します.開始ノードは,最初に実行する判定または処理ノードの番号を指し示すものです.
int initial_node;
などとします.
次に,判定ノードと処理ノードの総数を,設計者が任意に設定します.これをNODE_SUMとします.総ノード数は問題の規模に応じて設定しますが,たとえば,図1のように4種類のノードが存在する場合,「平均的に各種5個ずつ」使用すると想定して総ノード数20個あたりからシミュレーションを開始します.
このとき,NODE_SUM個のノードはかんたんに,
struct gene_structure gene[NODE_SUM];
で用意することができます.
GNPは進化論的計算手法ですので,複数の個体を用意する必要があります.したがって,実際には個体数(IND)の分だけ遺伝子を用意します.
| int initial_node[IND]; /* 全個体分の開始ノード番号 */ struct gene_structure gene[IND][NODE_SUM]; /* 全個体分の判定ノードと処理ノード */ |
2. 個体の初期化
初期世代の個体を生成するために,ノード変数の初期化を行います.ノードの種類(判定・処理),ノード関数をランダムに割当て,任意の遅れ時間を設定し,接続先もランダムに決定します.各個体,開始ノードを1個,判定ノードと処理ノードを合わせてNODE_SUM個使用すると仮定すると,
| for (int ind; ind<IND; ind++) { /* 全個体について初期化ループ
*/ initial_node[ind]=rand()%NODE_SUM; /* 開始ノードの初期化.最初に実行するノードの番号をランダムに割当てる (修正:14/07/08) */ for (int node_num=0; node_num<NODE_SUM; node_num++) { /* 全ノードについて初期化ループ */ /* ノード関数の設定 */ if (node_num<JUDGE_SUM) { gene[ind][node_num].node_type=0; /* あらかじめ決められた数の判定ノードを用意する 注2*/ } else { gene[ind][node_num].node_type=1; /* あらかじめ決められた数の処理ノードを用意する 注2*/ } if (gene[ind][node_num].node_type==0) { gene[ind][node_num].node_func=rand()%JUDGE; /* JUDGEはノード関数の数.図1では2個 注3 */ gene[ind][node_num].node_delay=1; /* 判定ノードの遅れ時間を1とする (任意)*/ } else { gene[ind][node_num].node_func=rand()%PROCESS; /* PROCESSはノード関数の数.図1では2個 注3 */ gene[ind][node_num].node_delay=5; /* 処理ノードの遅れ時間を5とする(任意) */ } /* 接続先の設定(判定・処理共通) */ for (int connect_num; connect_num<NUM_BRANCH; connect_num++) { do { gene[ind][node_num].connect[connect_num]=rand()%NODE_SUM; /* すべてのノード番号からランダムに次ノード番号を決定する */ }while (gene[ind][node_num].connect[connect_num]==node_num); /* 自己ループは禁止する */ } } } |
これで,すべてのノードが初期化され,IND個の有向グラフ構造が生成されます.
注2 判定ノードの番号は0からJUDGE_SUM-1, 処理ノードの番号はJUDGE_SUMからNODE_SUM-1
注3 上の例では,ノード関数をランダムに割り当てましたが,大きすぎる自由度がかえって探索を困難にすることも分かっており,あらかじめ決められた数のノード関数を割当てる方が性能が良いことがあります.たとえば,図1であれば判定ノード・処理ノードをあわせて4種類ありますので,各種5ノードずつ用意し,総ノード数20から実験を開始することが考えられます.最適なノード数の決定法については現在のところ問題の複雑さを考慮して決定するというところにとどまっています.
プログラムの実行(ノード遷移)
個体番号ind(0<=ind<IND, IND: 個体数)を実行する手順を説明します.
1.実行中のノード(カレントノード)の番号を表す変数を宣言します.
int current;
2.開始ノードの情報にしたがって最初に実行するノードの番号を格納します.
current=initial_node[ind];
3.判定ノードまたは処理ノードの内容を実行して,次のノードに進みます.
以上をまとめると,全個体のプログラム実行(ノード遷移)の流れは以下のようになります.
| int current; int judge_result; for (int ind; ind<IND; ind++) { current=initial_node[ind]; for (int step=0; step<TIME_LIMIT;) { if (gene[ind][current].node_type==0) { judge_result=judge(ind, current); /* 判定ノードを実行し,判定結果を返す 判定関数judge(int ind, int current)は問題に応じて作成する */ } else if (gene[ind][current].node_type==1) { process(ind, current); /* 処理ノードを実行する 処理関数judge(int ind, int current)は問題に応じて作成する */ judge_result=0; /* 処理ノードは常に1番目の接続遺伝子情報を利用する */ } step+=gene[ind][current].node_delay; current=gene[ind][current].connect[judge_result]; /* 次のノードへ遷移する */ } } |
遺伝的操作
遺伝的操作には,交叉と突然変異があります.
これまでの研究では,交叉と突然変異を同個体に適用すると,破壊的な構造変化となる可能性があるため,交叉で生成する個体数と,突然変異で生成する個体数を設定しています.たとえば,交叉個体数120,
突然変異個体数180などとします.
交叉
1.適合度に基づき,任意の選択法を用いて2個体を選択します.
2.ノード番号1から順番に,そのノード番号の遺伝子を交換するかどうか交叉確率Pcで決定します.
3.たとえばノード番号iのノードを交叉する場合,2個体間ですべての遺伝子を交換します.
| for (int node_num=0; node_num<NODE_SUM; node_num++) { /* すべてのノード番号についてそれぞれ独立に交叉を行う(一様交叉)
*/ if ( ((double)rand()/RAND_MAX)<CROSSOVER_RATE ) { /* 交叉確率に基づいてノード番号node_numを交叉対象とするかどうか決定する */ gene_temp[node_num]=gene_parent1[node_num]; /* 2個体間で遺伝子をswap */ gene_parent1[node_num]=gene_parent2[node_num]; gene_parent2[node_num]=gene_temp[node_num]; } } |
※以上の交叉プログラムは,サンプルプログラムとやや異なります.機能は同じです.
突然変異
1.適合度の基づき,任意の選択法を用いて1個体を選択します.
接続の突然変異
2.全てのノードの全てのブランチに対して独立に,突然変異確率Pmで突然変異を行うブランチとして選択する.
3.選択されたブランチをランダムに選ばれた他のノードに接続する.
ノード関数の突然変異
4.全てのノードに対して独立に,突然変異確率Pmで突然変異を行うノードとして選択する.
5.選択されたノードの関数をランダムに変更する.ただし,処理ノードから判定ノードに変わることはない.逆も同様.
| for (int node_num=0; node_num<NODE_SUM; node_num++) { /* すべてのノード番号についてそれぞれ独立に突然変異を行う
*/ /* 接続の突然変異 */ for (int connect_num; connect_num<NUM_BRANCH; connect_num++) {/* 各接続ブランチごとに突然変異処理を行う 注4*/ if ( ((double)rand()/RAND_MAX)<MUTATION_RATE ) { /* 突然変異確率に基づいて突然変異対象とするかどうか決定する */ do { gene[ind][node_num].connect[connect_num]=rand()/NODE_SUM; /* すべてのノード番号からランダムに次ノード番号を決定する */ }while (gene_temp[mutation][node_num].connect[connect_num]==node_num); /* 自己ループは禁止する */ } /* ノード関数の突然変異 */ if ( ((double)rand()/RAND_MAX)<MUTATION_RATE ) { /* 突然変異確率に基づいて突然変異対象とするかどうか決定する */ if (gene[ind][node_num].node_type==0) { gene[ind][node_num].node_func=rand()/JUDGE; /* 判定ノードの場合,ランダムに判定関数を変更する.JUDGEは判定関数の数 */ } if (gene[ind][node_num].node_type==1) { gene[ind][node_num].node_func=rand()/PROCESS; /* 処理ノードの場合,ランダムに判定関数を変更する.PROCESSは処理関数の数 */ } } } |
注4 上のソースコードでは,表記をなるべくシンプルにするために,判定ノードと処理ノードの接続の突然変異を同じループに入れていますが,処理ノードでは接続を1本しか使わない点で無駄なループが生じます.
参考文献
[1] J. H. Holland: Adaptation in Natural and Artificial Systems, University
of Michigan Press, 1975
[2] J. R. Koza: Genetic Programming: On the Programming of Computers by
Means of Natural Selection, MIT Press. 1992
[3] S. Mabu, K. Hirasawa and J. Hu: A graph-based evolutionary algorithm:
Genetic Network Programming (GNP) and its extension using reinforcement
learning, Evolutionary Computation, Vol. 15, No. 3, pp. 369-398, 2007
[4] 間普 真吾,平澤宏太郎: 遺伝的ネットワークプログラミングのアーキテクチャについて,システム制御情報学会誌,
システム/制御/情報,Vol. 55, No. 11, pp. 480-485, 2011
Copyright(C) 2014 Shingo Mabu, Graduate School of Science and Enginerring, Yamaguchi University All Rights Reserved.
2014.04.14更新